The last post was about architecture decisions.
This one is about execution.
I spent this cycle turning ideas into something runnable and testable. Not polished. Not “AI magic.” Just real foundations.
What shipped since the last post
1) REST API vertical slice
navi-agent now has a working API backbone with health, task, and agent routes, including sync flow.
This gave me a full path from request → service → persistence → response, which is where real design flaws start to show up.
2) SQLite persistence for tasks and agents
I moved core state out of memory and into SQLite for both tasks and agent metadata.
That sounds simple, but it changes everything: restart behavior, debugging, and confidence in iterative testing.
3) Real agent sync + data-defined agent loading
Agent sync is no longer fake.
Agents are loaded from filesystem definitions and synced into persistence.
This aligns with the core principle of navi-agent: agents are data, not hardcoded logic.
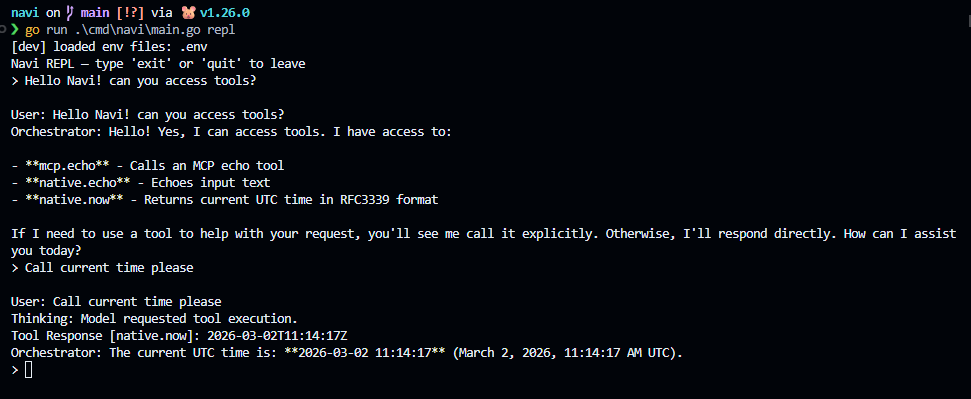
4) REPL/TUI loop for fast local testing
I added a simple REPL to exercise behavior quickly without bouncing through HTTP every time.
Current focus is making outputs explicit so it’s obvious what is:
- user message
- model “thinking” signal
- tool response
- orchestrator final answer
That visibility matters more than pretty UI right now.
5) Sprint 1 orchestrator loop + tool calling
I implemented a basic orchestrator loop where the model can request tools through a structured tool-call format, tools execute, and results feed back into the next turn.
It supports single and multi-tool call patterns in the same exchange.
6) Basic MCP integration path
A minimal MCP path is wired for tool execution flow, enough to validate the architecture direction without overbuilding too early.
7) Dev onboarding improved with .env
Fresh clone experience now supports .env-based local setup for:
- API key
- default provider
- default model
- environment mode (
development/production)
On startup in development mode, navi-agent prints which .env files were loaded.
No guessing, no “why is this config not applying?” confusion.
8) First-launch config directory creation is explicit
navi-agent now creates its user config directory on first launch before command execution.
That removes a bunch of hidden friction for first-time contributors.
Tool calling test
Logging decision (important)
I had a long architecture discussion about telemetry, and I’m choosing the pragmatic path:
- No OpenTelemetry for now
- Use Go native
log/slog - Structured JSON Lines (
.jsonl) local logs - Rotation
- Make logs easy for MCP tools to inspect
Why: navi-agent is local-first right now. I want observability without dependency bloat or complexity tax.
This keeps things minimal, testable, and future-proof.
Process note: architect + AI pair execution
I rewrote this project multiple times. Prototype → refactor → miss → rewrite again.
That’s not chaos anymore. It’s intentional process.
I’m running an XP-like loop with AI pair programming:
- I own architecture, boundaries, and trade-offs.
- AI accelerates implementation, test iteration, and mechanical refactors.
So rewrites are not failure signals. They are part of design convergence.
Sprint remodel (updated)
Sprint 1 — Single-agent runtime stability (current)
- Simple navi-agent TUI ✅
- Basic main orchestrator agent ✅
- Basic tool calling ✅
- Basic MCP integration ✅
- .env onboarding ✅
- Agent configuration folder requirements revision/re-think ⏳
- Logging foundation (
slog+ JSONL) ⏳
Goal: TUI asks model to use tools and tool flow is reliable/observable.
Sprint 2 — Specialist vertical slice (no full agency yet)
- Basic specialist agents: planner, researcher, coder, tester (one active at a time)
- Basic native MCP tools expansion
- More CLI commands
- TUI UX improvements (clarity, traceability, consistency)
Goal: TUI can call MCP tools and route to one specialist agent per turn.
Sprint 3 — Agency rollout
- Controlled multi-agent delegation
- Guardrails (limits, failure policy, recovery paths)
- Better orchestration timeline/debug view
Goal: multi-agent coordination with predictable behavior and debuggable traces.
Infrastructure survives hype cycles.
So I’m building infrastructure first.
If you’re building local-first AI tooling too, I’d love your feedback on the logging direction and sprint structure.